How To Identify Rare Surnames In Your Family Tree
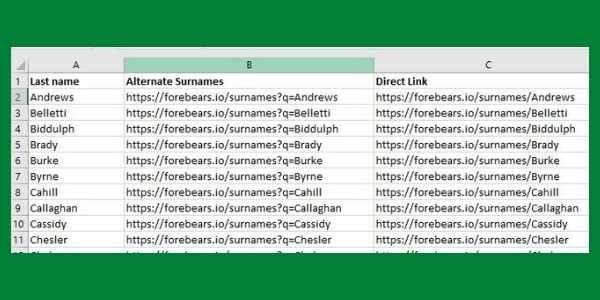
When you’re building your family tree, the rarer surnames are often the easiest to research. My grandmother was a Smith which makes that ancestral line a challenge to explore. My early research focused on marriages in the Smith line to people with less common last names. This tutorial shows you how to use a spreadsheet … Read more